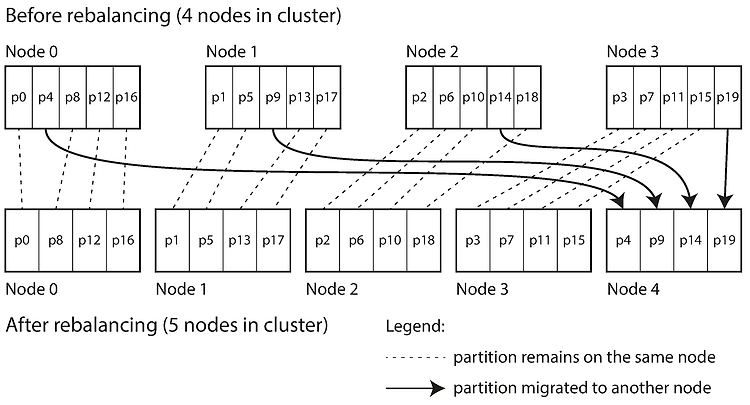
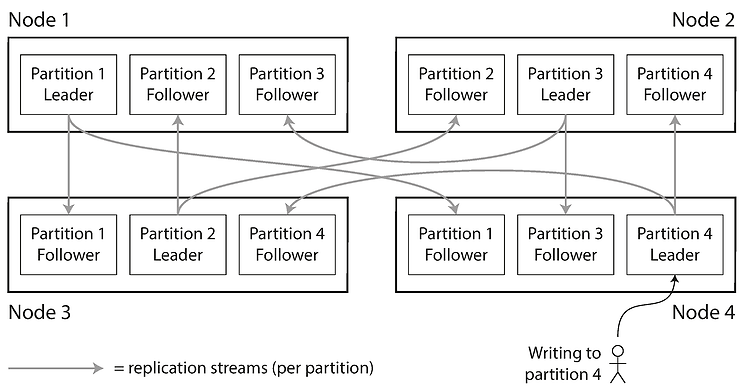
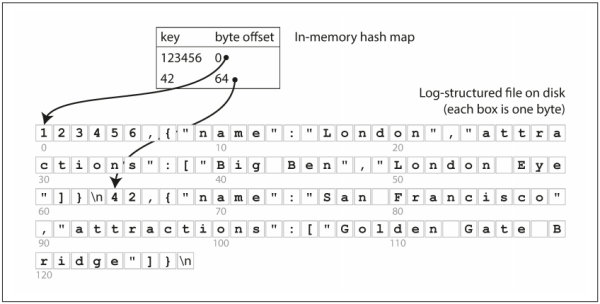
파티셔닝(Partitioning) 이전 포스트에 이어서 파티셔닝에서 사용하는 리밸런싱 기법에 관해 살펴보고, 클라이언트에서 질의 요청을 어떻게 처리할 것인지에 관해 알아보겠습니다. 파티션 리밸런싱 리밸런싱이란 클러스터에서 한 노드가 담당하던 부하를 다른 노드를 옮기는 과정입니다. 이러한 리밸런싱이 필요한 경우는 시간이 지나면서 데이터베이스에 변화가 생기기 때문입니다. 예를 들어 질의 처리량이 증가하여 부하를 늘리기 위해 CPU를 추가하거나, 데이터 셋의 크기가 증가하여 디스크와 램을 추가 하는 등의 변화입니다. 이러한 리밸런싱을 위한 전략이 몇가지가 있습니다. 리밸런싱 전략 쓰면 안되는 방법: 해시값 mod N mod 연산을 사용하면 쉽게 각 키를 노드에 할당하는 것이 쉽다. 예를 들어 노드가 10대가 ..