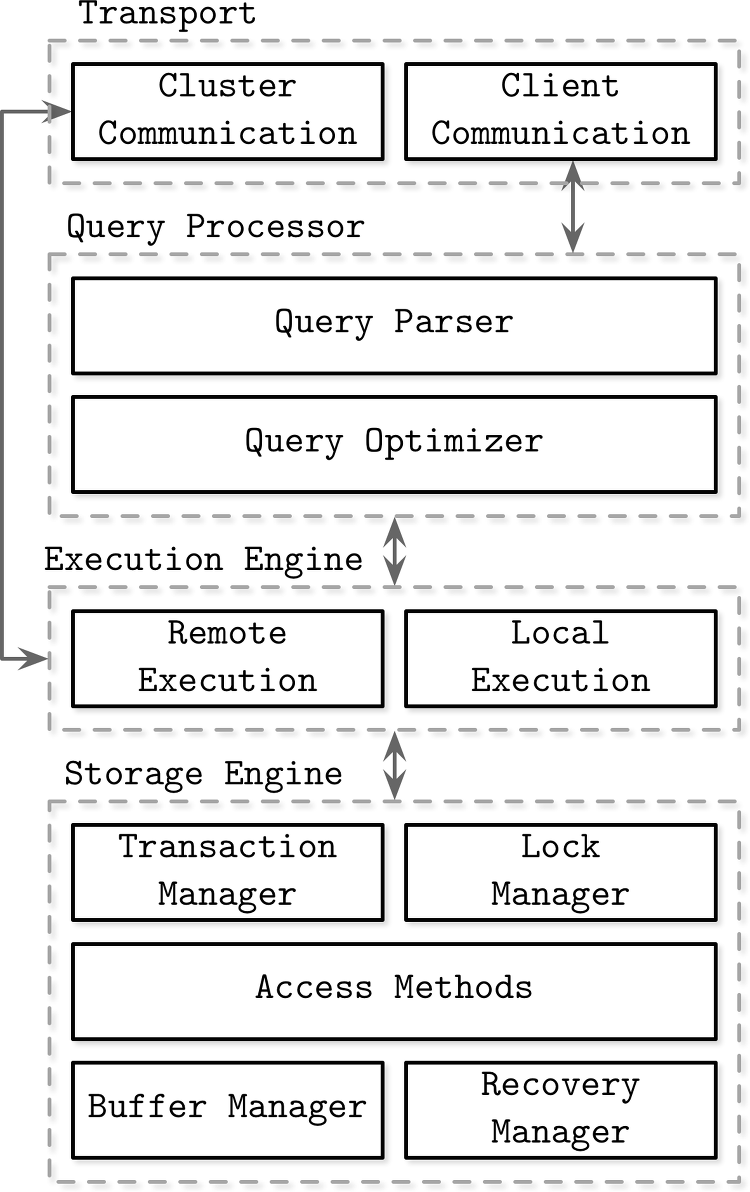
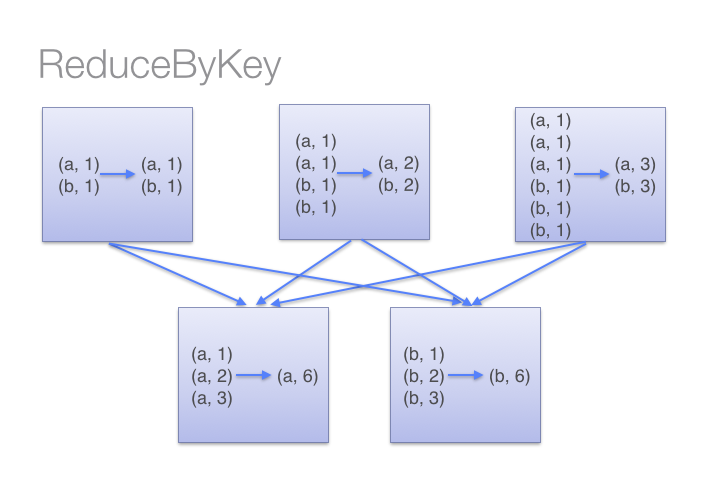
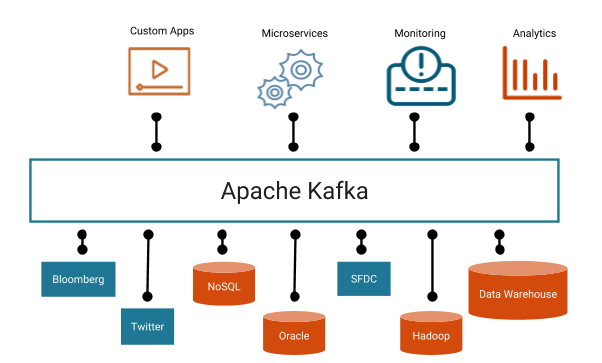
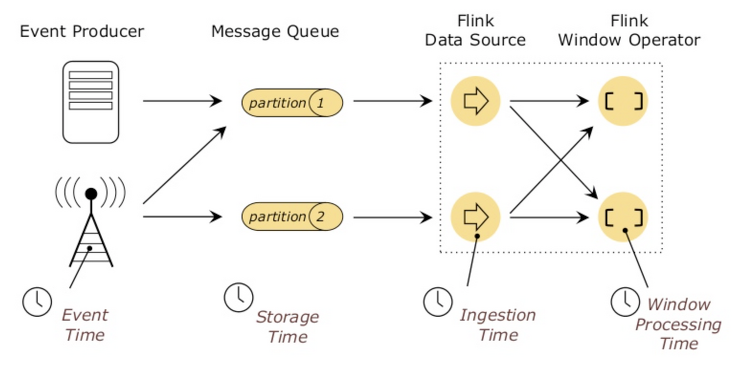
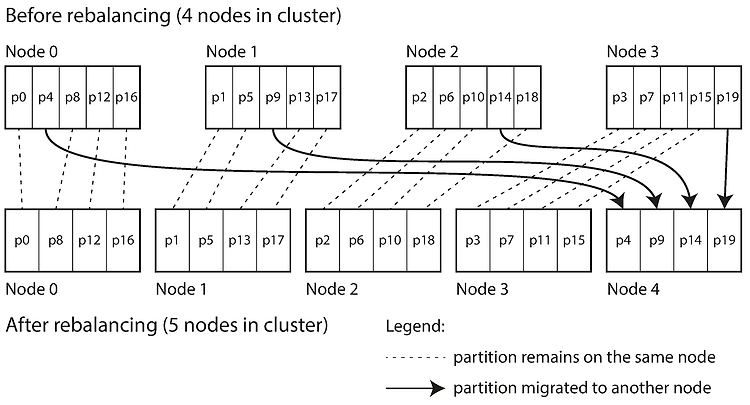
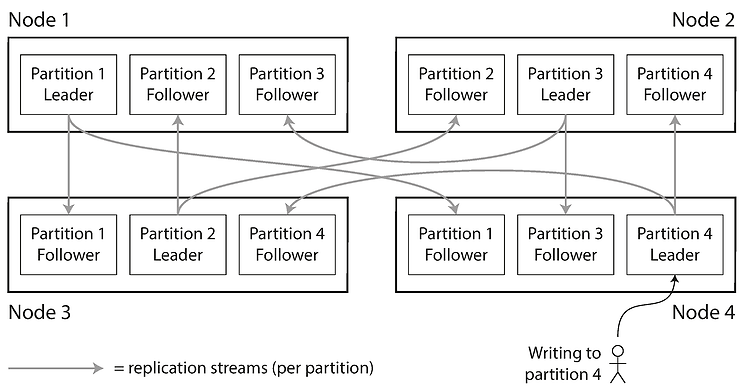
데이터베이스 시스템의 선택은 중요합니다. 성능, 일관성 문제, 운영의 어려움과 같은 이유로 데이터베이스를 변경하게 되는 경우가 발생할 수 있습니다. 데이터베이스를 변경할 때 마이그레이션이 쉽지 않을 수도 있기 때문에 초기 설계 단계에서 애플리케이션의 특성에 알맞는 데이터베이스를 선택해야 합니다. 데이터베이스를 선택함에 있어 다음과 같은 변수를 통해서 어떤 데이터베이스를 선택할지 예측할 수 있습니다. 스키마와 레코드 크기 클라이언트 수 쿼리 형식과 접근 패턴 읽기와 쓰기 쿼리 비율 위 변수들의 변동폭 그리고 위의 변수들을 기준으로 다음과 같은 체크리스트에 관한 답을 내려서 선택할 수 있습니다. 요청된 쿼리를 수행할 수 있는가? 데이터를 모두 저장할 수 있는가? 단일 노드는 몇 건의 읽기와 쓰기 요청을 처리..