벌써 4번째 포스트입니다. 3장 저장소와 검색은 정리하면서 중요한 개념들이 많이 나와 있어 자세히 정리를 하고 있습니다. 이번 포스트에서는 데이터베이스에 접근하는 방식의 차이에 따라 구분되는 온라인 트랜잭션 처리(online transaction processing, OLTP)와 온라인 분석 처리(online anlaytic processing, OLAP)에 관해 살펴보겠습니다.
트랜잭션 처리와 분석 처리
초창기 비즈니스 데이터 처리는 데이터베이스 쓰기가 보통 상거래(commercial transaction)에 해당했습니다. 그러나 이러한 상거래가 아닌 영역으로 데이터베이스가 확장되었어도 트랜잭션이라는 용어는 그대로 사용하고 있습니다. 데이터베이스에서 트랜잭션은 논리 단위로 읽기와 쓰기와 같은 상호작용의 단위입니다.
데이터베이스의 기본적인 접근 패턴은 키에 대한 레코드를 찾거나 사용자 입력을 기반으로 삽입되거나 갱신되는 형태입니다. 애플리케이션과 대화식으로 접근하기 때문에 이러한 접근 패턴을 OLTP라고 합니다. 그러나 점차 데이터베이스를 데이터 분석에도 많이 사용하기 시작했습니다. 분석 질의의 경우 많은 수의 레코드를 스캔해 레코드당 일부 칼럼을 읽어 집계를 하는 경우가 하나의 예입니다. 이러한 질의는 보통 비즈니스 분석가가 작성하며 회사 경연진이 더 나은 의사 결정을 돕도록 합니다(비즈니스 인텔리전스라고 함). 이렇게 데이터베이스 사용 패턴을 트랜잭션 처리와 구별하기 위해 OLAP이라고 부릅니다. OLTP와 OLAP을 비교하는 표는 아래와 같습니다.
| 특성 | OLTP | OLAP |
| 읽기 패턴 | 질의당 적은 수의 레코드, 키를 기준으로 가져옴 | 많은 레코드에 대한 집계 |
| 쓰기 패턴 | 랜덤 엑세스, 낮은 지연 시간으로 기록 | bulk import(ETL) 혹은 이벤트 스트림 |
| 사용처 | 웹 애플리케이션을 통한 사용자 | 의사 결정 지원을 위한 분석가 |
| 데이터가 나타내는 것 | 데이터의 최신 상태(현재 시점) | 시간이 지나며 일어난 이벤트 이력 |
| 데이터셋 크기 | 기가바이트에서 테라바이트 사이 | 테라바이트에서 페타바이트 |
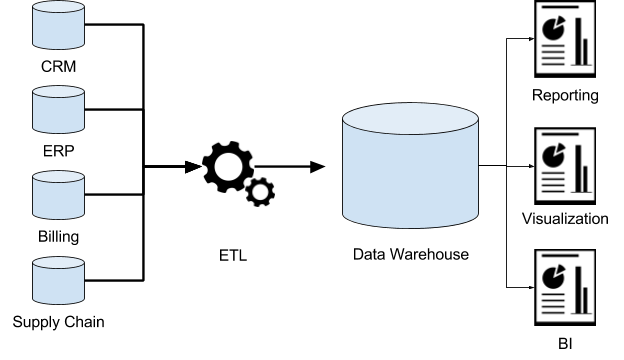
처음에는 OLTP와 OLAP을 동일한 데이터베이스를 사용하였지만 최근에는 OLTP와 OLAP의 데이터베이스를 구분해서 사용하는 경향을 보이고 있습니다. 그중에 OLAP을 목적으로 하는 데이터베이스를 데이터 웨어하우스라고 합니다.
데이터 웨어하우스
OLTP 시스템은 보통 운영에 대단히 중요하기 때문에 높은 가용성과 낮은 지연의 트랜잭션 처리를 기대합니다. 그렇기 때문에 비즈니스 분석가가 OLTP 데이터베이스에 ad hoc 분석 질의를 실행을 하는 것을 꺼려합니다. 이러한 질의는 비용이 많이 들기 때문입니다. 그러한 이유로 데이터 웨어하우스를 따로 두어서 분석 질의를 처리하도록 합니다. 데이터 웨어하우스는 분석가들이 OLTP 시스템에 영향을 주지 않고 편하게 분석 질의를 날릴 수 있는 데이터베이스입니다. 이러한 데이터 웨어하우스는 OTPL 데이터베이스의 읽기 전용 복사본과 같습니다. 물론 분석을 위해서 중간에 변환 과정도 거치게 됩니다. 그래서 OTPL 데이스베이스에서 데이터를 추출(extract)하고 분석에 유리한 스키마로 변환(transform)을 해서 데이터 웨어하우스에 적재(load)를 하게 됩니다. 이러한 과정을 보통 ETL(Extract-Transform-Load)라고 합니다.
칼럼 지향 저장소
분석에서 사용되는 데이터 모델을 그렇게 많지 않습니다. 데이터 웨어하우스는 star schema를 주로 사용합니다. 이 스키마는 스키마 중심에 fact table이 있고 fact table의 칼럼이 참조하고 있는 여러 개의 dimension table이 존재합니다. 이 모양이 별 모양을 하고 있기 때문에 star schema라고 합니다. fact table의 row는 특정 시간에 발생한 이벤트를 나타내고 dimension은 이벤트의 속성을 나타냅니다.
fact table에는 엄청난 개수의 row와 페타바이트 데이터가 있으며 효율적으로 저장하고 질의하기 위해선 고민이 필요합니다. fact table에는 수백 개 이상의 칼럼이 존재하는게 보통이지만 분석 질의의 경우 대부분 4-5개의 컬럼만을 접근합니다. 그러나 기존의 OLTP 데이터베이스의 경우 로우 지향이고 이는 테이블에서 한 로우의 모든 값을 서로 인접하게 저장을 함을 의미합니다. 이와 같이 분석 질의를 로우 지향 저장소에 요청하는 경우 모든 컬럼을 메모리에 적재한 다음 필요한 컬럼을 필터링해야 합니다. 이 작업은 오랜 시간이 걸릴 것입니다.
컬럼 지향 저장소는 칼럼별로 값을 저장하는 것이 기본 개념입니다. 각 칼럼을 개별 파일에 저장하면 질의에 사용되는 칼럼만 읽고 구문 분석만 하면 됩니다. 그리고 칼럼 지향 저장소는 또 다른 장점을 가집니다. 칼럼 별로 데이터를 저장하기 때문에 뛰어난 압축률을 보여줍니다. 이렇게 칼럼 지향 저장소는 분석 질의를 효과적으로 처리할 수 있습니다.
정리
총 4번의 포스트에 걸쳐 데이터베이스가 어떻게 데이터를 저장하고 그 데이터를 조회하는지 알아보았습니다. 저장소 엔진은 트랜잭션 처리 최적화(OLTP)를 위한 엔진과 분석 최적화(OLAP)를 위한 엔진 두가지로 나뉜다고 볼 수 있습니다. OLTP 측면에서 2가지 관점으로 살펴보았습니다. 첫 번째는 log-structured 관점이었고, 두 번째는 update-in-place 입니다. 로그 구조화 저장소 엔진은 주로 SS테이블, LSM 트리, 레벨 DB, 카산드라, HBase, 루씬이 이 그룹에 속하고, update-in-place의 가장 큰 예는 B 트리가 가장 큰 예입니다. B 트리는 주요 관계형 데이터베이스에와 많은 비정형 데이터베이스에서도 사용합니다.
이와 같이 저장소 엔진의 내부에 대한 지식이 있다면 애플리케이션 개발에 있어서 어떤 저장소 엔진을 사용하는게 적합한지 판단할 수 있습니다. 그렇기 때문에 이와 같은 데이터 저장소에 대한 내부 지식을 알고 있으면 굉장히 유용할 것입니다.
'Big Data > Designing Data-Intensive Applicatiosn' 카테고리의 다른 글
| 05. 복제(Replication) - 1 (0) | 2019.11.18 |
|---|---|
| 04. 인코딩(Encoding)과 발전(Evolution) (0) | 2019.09.15 |
| 03. 저장소(Storage)와 검색(Retrieval) - 3 (0) | 2019.08.26 |
| 03. 저장소(Storage)와 검색(Retrieval) - 2 (0) | 2019.08.21 |
| 03. 저장소(Storage)와 검색(Retrieval) - 1 (0) | 2019.08.18 |