이번 장의 주제는 복제(Replication)입니다. 복제란 네트워크로 연결된 여러 장비에 동일한 데이터의 복사본을 유지하는 것을 의미합니다. 복제를 통한 이점은 다양합니다. 첫째로, 지리적으로 사용자와 가까운 곳에 데이터가 존재할 수 있어서 지연 시간(latency)을 줄여줍니다. 둘째로, 시스템에 일부 장애가 발생해도 지속적으로 동작할 수 있게 해 가용성(availability)를 높여줍니다. 셋째로, 데이터를 여러 장비로부터 읽을 수 있어서 처리량을 늘려줍니다.
이번 장에서는 노드간 변경을 복제하기 위한 세 가지 접근 방법인 싱글 리더, 멀티 리더, 리더리스 복제에 대해 살펴볼 예정입니다. 또한 복제에 고려해야 할 트레이드오프가 존재하는데 예를 들어 동기식 복제와 비동기식 복제 중 어떤 것을 사용할지, 잘못된 복제본이 있다면 어떻게 처리해야 할지와 같은 것입니다.
싱글 리더 (single-leader)
싱글 리더를 살펴보기 전에 간단히 복제와 관련된 용어에 대해 알아보겠습니다.
| 용어 | 의미 |
| 복제 서버(replica) | 데이터베이스의 복사본을 저장하는 노드 |
| 리더 기반 복제(active/passive, master/slave 복제) | 복제 서버 중 하나가 리더(마스터, 프라이머리)가 되어 동일 데이터 유지 |
| 팔로워(read replica, slave, secondary) | 리더가 아닌 복제 서버 |
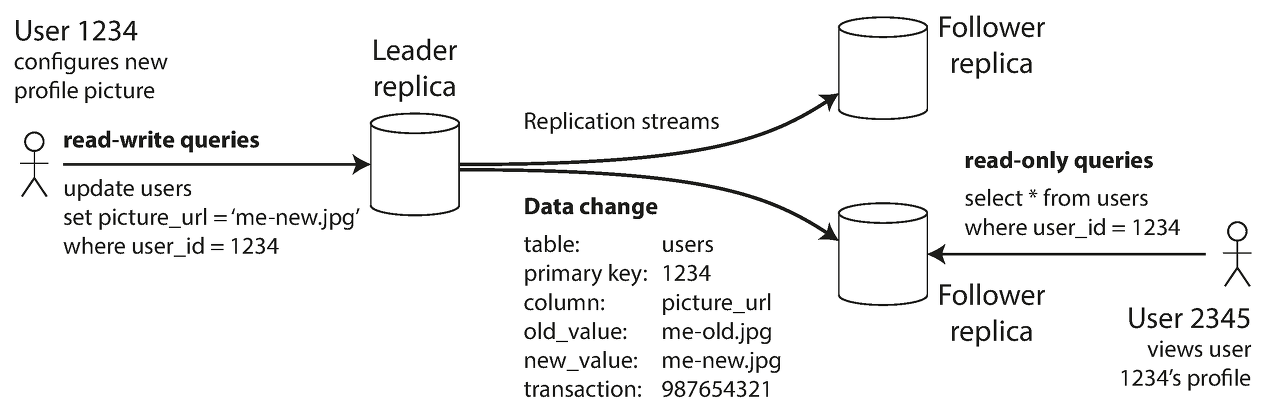
싱글 리더는 복제 서버들 중 하나가 리더가 되서 데이터의 복사본을 유지하는 것입니다. 클라이언트가 데이터베이스에 쓰기 요청을 하면 요청은 리더에게 보내지고 리더는 먼저 로컬에 새로운 데이터를 기록합니다. 리더는 로컬 저장소에 새로운 데이터를 쓸 때마다 데이터의 변경을 replication log나 change stream의 일부를 팔로워에게 전송하고 각각의 팔로워들은 리더가 처리한 것과 동일한 순서로 모든 쓰기를 적용해 복사본을 갱신합니다.
아래의 그림과 같이 읽기는 리더나 팔로워에게 요청 가능하지만 쓰기는 리더에게만 허용됩니다.
멀티 리더 (multi-leader)
싱글 리더 복제에 주요한 단점 하나가 있는데 리더가 하나만 존재하고 모든 쓰기는 리더를 거쳐야 한다는 것입니다. 멀티 리더 방식은 쓰기 처리를 하는 노드를 하나 이상 두는 방식이다. 이를 멀티 리더(master-master 혹은 active/active 복제라고도 함) 설정이라고 합니다. 이 방식에서는 각 리더는 동시에 다른 리더의 팔로워 역할을 함께 수행합니다.
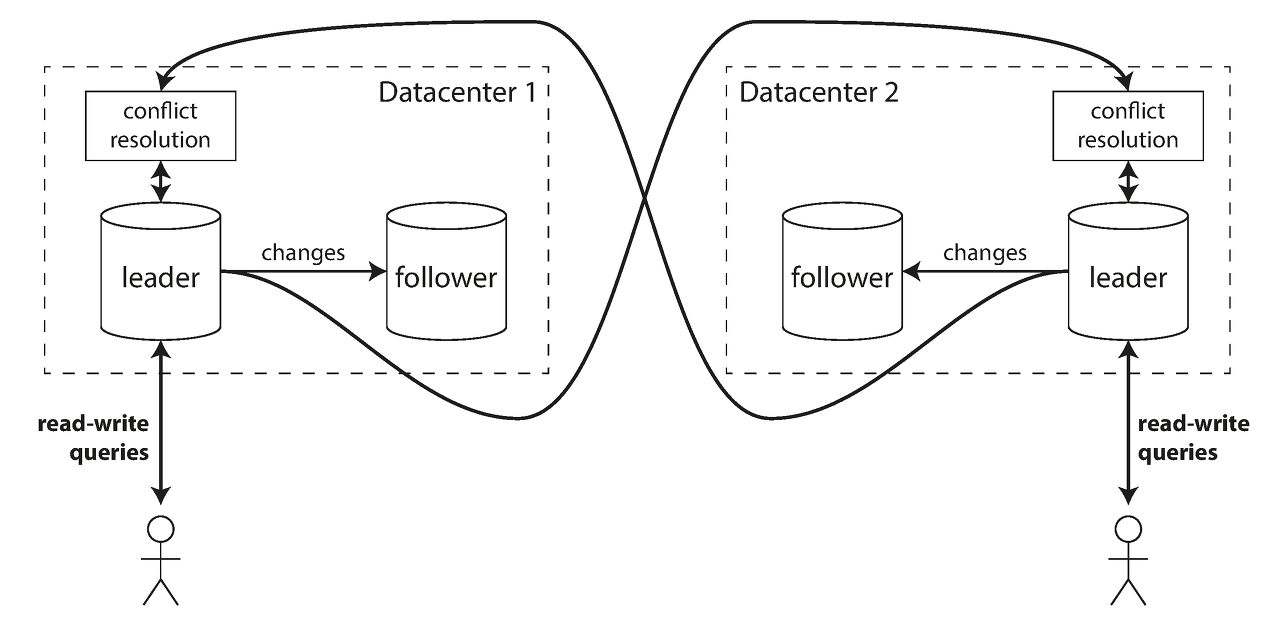
멀티 리더의 경우는 주로 여러 데이터센터를 운영할 때 사용합니다. 다중 데이터 센터에 데이터베이스 복제 서버가 존재하는 경우는 데이터센터의 내결함성을 갖추기 위하거나 지리적으로 사용자에게 가까이 위치하기 위해서 구성합니다. 이와 같이 구성하게 되면 다음과 같은 장점을 가지게 됩니다.
- 멀티 리더가 모든 쓰기는 각 데이터센터에서 처리하고 후에 복사본은 비동기 방식(뒤에서 설명)으로 처리하면 사용자가 인지하는 성능은 더 좋아지게 됩니다.
- 데이터센터마다 리더가 존재하기 때문에 독립적으로 동작하고 하나의 데이터센터가 고장 나도 온라인으로 돌아왔을 때 복제를 따라잡을 수 있습니다.
그러나 멀티 리더 복제의 경우 동일한 데이터를 다른 두 개의 데이터센터에서 동시에 변경할 수 있기 때문에 이때 발생하는 쓰기 충돌을 해결해야 합니다.
쓰기 충돌 다루기
다중 리더 복제에서 가장 큰 문제는 쓰기 충돌이 발생하는 것입니다. 이는 이 충돌 해결이 필요하다는 이야기입니다. 멀티 리더 설정에서는 두 쓰기가 모두 성공하며 충돌은 이후 특정 시점에서 비동기로 감지가 가능한데 이 경우 사용자에게 충돌 해소를 요청하면 너무 늦을 수 있습니다. 충돌을 처리하는 방법은 다음과 같습니다.
- 충돌 회피 : 특정 레코드의 모든 쓰기가 동일한 리더를 거치도록 애플리케이션이 보장
- 일관된 상태 수렴 : 데이터베이스에 데이터가 최종적으로 수렴(convergent)하는 방식으로 충돌 해결
- 예 : 타임스탬프를 사용한 최종 쓰기가 저장되는 방식, 고유 ID 부여, 데이터 병합, 충돌 기록 후 사용자가 해결하도록 제공 등 - 사용자 정의 충돌 해결 로직 : 사용자가 애플리케이션 코드에서 충돌 해결 로직을 작성하도록 하는 방법
리더리스(leaderless) 복제
리더리스 복제는 클라이언트의 쓰기가 리더가 아닌 여러 복제 서버에 쓰기를 직접 전송하는 방식입니다. 클라이언트에서는 오래된 데이터를 감지하고 이를 바로잡기 위해 병렬로 여러 노드에서 데이터를 읽습니다. 일부 데이터스토어에서는 백그라운드 프로세스를 두어서 복제 서버 간 데이터 차이를 지속적으로 찾아 다른 복제 서버로 복사합니다. 이러한 방식은 안티 엔트로피 처리 방식이라고 합니다. 이 방식은 복제 로그와 달리 특정 순서로 쓰기를 복사하기 때문에 데이터가 복사되기까지 상당한 지연이 발생할 수 있습니다.
리더리스 복제 방식에서는 읽기와 쓰기를 위해 필요한 최소의 투표수가 필요합니다. 즉 여러 복제 서버들로부터 데이터를 읽거나 쓰는 경우 최소 얼마 이상의 투표가 이루어져야지 정상적으로 데이터를 읽은 것이나 쓴 것이라고 판단합니다. 이와 같이 정상적인 상태인 것을 판단하기 위해서 필요한 최소 투표수를 정족수(quorum)라고 합니다.
리더리스의 경우 정족수 조건이 다양하기 때문에 애플리케이션 특성에 맞춰 읽기와 쓰기 정족수를 설정해야 합니다.
이번 포스트에서는 고가용성과, 네트워크 중단, 지연, 확장을 위해서 사용하는 복제의 대해 살펴보았습니다. 이러한 복제 기능을 제공하기 위해 3가지 주요한 접근 방법에 대해 알아보았습니다. 싱글 리더, 멀티 리더, 리더리스가 바로 그 방식입니다. 각 접근 방식마다 장단점이 존재하는데 단일 리더 복제는 이해하기 쉽고 충돌 해소에 우려가 없어서 널리 사용됩니다. 멀티 리더나 리더리스의 경우 결함 노드나 네트워크 중단, 지연 시간 증가의 문제에 견고하지만 이해하기 어렵고 일관성 보장이 어렵다는 것이 단점입니다.
다음 포스트에서는 이어서 복제가 어떠한 방식으로 동작하는지에 대해 알아보겠습니다.
'Big Data > Designing Data-Intensive Applicatiosn' 카테고리의 다른 글
| 06. 파티셔닝(Partitioning) - 1 (0) | 2020.11.24 |
|---|---|
| 05. 복제(Replication) - 2 (1) | 2019.12.20 |
| 04. 인코딩(Encoding)과 발전(Evolution) (0) | 2019.09.15 |
| 03. 저장소(Storage)와 검색(Retrieval) - 4 (0) | 2019.09.05 |
| 03. 저장소(Storage)와 검색(Retrieval) - 3 (0) | 2019.08.26 |