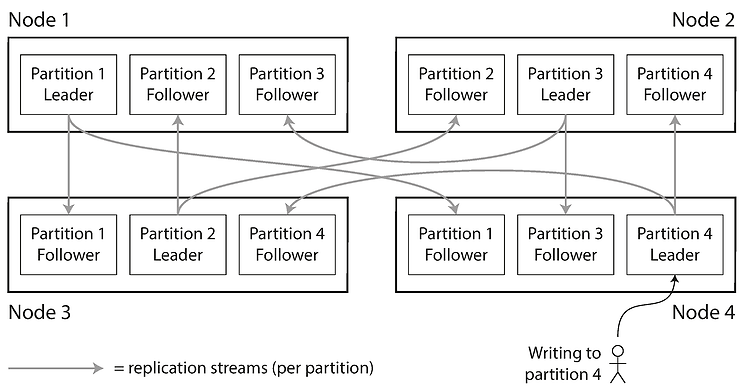
데이터셋이 매우 크거나 질의 처리량이 매우 높은 경우 데이터를 파티션으로 쪼개야 합니다. 이번 포스트에서 이야기하는 파티셔닝은 대용량 데이터베이스에서 데이터를 작은 단위로 쪼개는 방법을 말합니다. 몽고DB, 엘라스틱서치, 솔라에서는 샤드라고 하며 HBase에서는 리전, 빅테이블에서는 태블릿(tablet), 카산드라와 리악에서는 vnode, 카우치베이스에서 vBucker이라고 부릅니다. 데이터 파티셔닝의 가장 큰 목적은 확장성을 갖기 위함입니다. 대용량 데이터셋을 파티셔닝하여 여러 디스크에 분산시킬 수 있고, 질의 부하를 분산시킬 수 있습니다. 주로 파티셔닝은 복제(Replication)와 함께 적용해 파티션의 복사본을 여러 노드에 저장합니다. 복제에 관한 설명은 이전 포스트에서 확인할 수 있습니다. 파티..